자사 언어 번역 모델의 개발과 사용이 유발할 수 있는 윤리적 문제를 지적한 논문을 발표했다는 이유로 해당 연구 직원을 퇴사시킨 구글의 최근 행보를 둘러싼 논란을 다룬 MIT 보고서 내용 정리.
MIT Technology Review (www.technologyreview.com/2020/12/04/1013294/google-ai-ethics-research-paper-forced-out-timnit-gebru/amp/)
12월 2일 수요일 저녁, 구글 윤리 AI 팀의 공동 리더인 팀닛 게브루(Timnit Gebru)는 트위터를 통해 구글이 자신을 강제 퇴사시켰다고 발표했다.
인공지능 윤리연구에서 널리 존중받고 있는 리더인 게브루는, 얼굴 인식 기술이 여성과 유색인종을 식별하는 데 있어 정확성이 떨어지기 때문에 그것을 활용하면 결국 이들을 차별할 수 있다고 주장한 획기적인 논문을 공동 집필한 것으로 알려진 인물이다. 그녀는 친목 그룹인 “인공지능 안의 블랙”을 공동으로 창립하는 등 기술 산업 분야에서 다른 목소리를 내는 챔피언이다. 그녀가 소속되어 있던 팀은 AI 분야에서 가장 큰 다양성을 지닌 팀들 중 하나이며, 그들 나름대로 많은 선두 그룹 전문가들을 포함하고 있다. 그 팀은 자주 주류 AI 관행에 도전하는 비판적인 작품을 만들어 내어서 업계 동료들의 부러움을 샀었다.
일련의 트윗과 유출된 이메일, 언론 기사들은 게브루의 퇴장이, 그녀가 공동 집필한 또 다른 논문을 둘러싼 갈등의 정점임을 보여주고 있다. 제프 딘(Jeff Dean) 구글 AI 대표는 (나중에 자신이 온라인에 공개한) 내부 이메일을 통해 동료들에게 문제의 논문이 "우리 심사 기준을 통과하지 못했다"면서, "게브루는 구글이 여러 조건을 충족시켜 주지 않으면 사임하겠다고 말했는데, 그 조건은 구글이 취하기를 꺼리는 것이었다"면서 해고 결정을 정당화 했다. 게브루는 트위터에서, 자신이 휴가에서 돌아와 고용 문제를 해결하기 위해 "마지막 데이트" 협상을 요청했었다고 밝혔다. 그런데 그녀가 돌아오기 전에 이미 지신의 회사 이메일 계정이 사라졌다는 것이다.
인공지능 윤리 분야의 다른 많은 리더들은 온라인상에서, 그녀가 AI 연구의 핵심 노선에 대해, 그리고 어쩌면 구글사의 순익(bottom line)에 대해 불편한 진실들을 밝혀냈기 때문에 회사가 그녀를 몰아냈다고 주장하고 있다. 현재 구글 직원 1400여 명과 지지자 1900여 명도 항의 서한에 서명한 상태다. ...
“예측하기 어려운[랜덤한 확률의] 앵무새의 위험성에 대하여: 언어 모델이 너무 큰 것은 아닐까?”(On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?)라는 제목의 이 논문은 대형 언어 모델의 위험성을 다루고 있다. ...
논문의 서론에 따르면, 저자들은 "그것들의 개발과 관련된 잠재적 위험과 이러한 위험을 완화하기 위한 전략에 충분한 사고가 선행되었는가를 묻는다". ...
다른 연구자들의 연구를 바탕으로 한 이 논문은 자연어 처리의 역사, 대형 언어 모델의 4 가지 주요 위험 요소들에 대한 개요, 추가 연구에 대한 제안 등을 제시한다. ...
1. 환경 및 비용 문제(Environmental and financial costs)
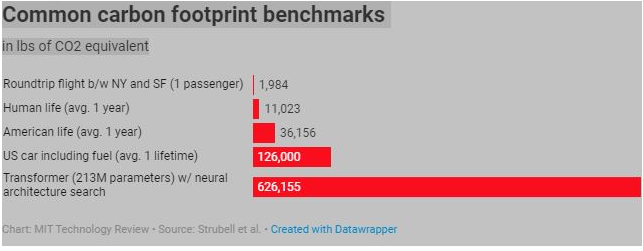
대형 AI 모델을 훈련시키는 일은 컴퓨터 처리 능력을 많이 사용하기 때문에 전력을 많이 소모한다. 게브루와 그녀의 공동저자는 엠마 슈트루벨과 그녀의 공동연구자들이 발표한 2019년 논문에서 대규모 언어 모델의 탄소배출량과 비용에 대해 언급하고 있다. 이 연구는 AI 모델들이 점점 더 많은 데이터를 공급받으면서 2017년 이후 에너지 소비량과 탄소 배출량이 폭발적으로 증가하고 있다는 사실을 지적했다.
슈트루벨의 연구는 특정한 유형의 "신경 건축술 검색" (NAS) 방법을 가진 하나의 언어 모델이 미국 자동차 5대의 평균 일생 배출량인 62만 6,155 파운드(284 미터 톤)의 이산화탄소를 발생시켰을 것이라고 주장했다. 구글의 검색엔진을 뒷받침하는 구글의 언어 모델인 BERT는 스트루벨의 추정치에 따르면 1,438 파운드의 CO2를 발생시켰는데, 이는 뉴욕시와 샌프란시스코 사이의 왕복 비행과 거의 같은 수준이다. ...

2. 대용량 데이터, 불가해한 모델
대형 언어 모델도 기하급수적으로 늘어나는 텍스트 양에 대해 [계속] 훈련받는다. 연구자들이 인터넷에서 가능한 모든 자료를 수집하고자 노력해 왔기 때문이다. 그래서 인종차별주의자나 성차별주의자의 언어 표현들, 욕설 등이 결국 훈련 자료에 포함될 위험이 존재한다.
인종차별적 언어를 정상으로 보는 법을 배운 인공지능 모델은 분명히 나쁜 것이다. 그러나 연구원들은 몇 가지 더 미묘한 문제점들을 지적한다. 그 중 하나는 언어의 변화가 사회 변화에 중요한 역할을 한다는 사실에 관한 것이다. 예를 들어, 미투와 블랙 라이프 매터 운동(the MeToo and Black Lives Matter movements)은 새로운 반-성차별적, 반-인종차별적인 어휘를 확립하기 위해 노력해왔다. 그러나 인터넷 언어의 방대한 단면들(swaths)에 대해 훈련받은 AI 모델은 그 같은 어휘의 뉘앙스에 올바로 적응하지 못할 것이며 이러한 새로운 문화적 규범에 부합하는 언어를 생산하거나 해석하지 못할 것이다.
또한 인터넷에 대한 접근성이 떨어지고 따라서 온라인상에서 언어 흔적을 남기기가 거의 어려운 나라들과 국민들의 언어와 규범을 포착하지 못할 것이다. 그 결과 AI가 만들어내는 언어는 가장 부유한 나라와 공동체들의 관행을 반영함으로써 균질화될 것이다. ...
"문서화하기에는 너무도 커다란 데이터 세트에 의존하는 방법론은 본질적으로 위험하다"고 연구자들은 결론짓는다. "문서화는 잠재적 책임성을 허용하지만 […] 문서화되지 않은 훈련 데이터는 상환의무를 거부한 채 영원히 해악을 행사한다." ...
3. 연구에 소요되는 기회 비용
셋째 문제점은 '잘못 방향지어진 연구 노력'(misdirected research effort)의 위험이라는 표현으로 요약된다. 대부분의 AI 연구자들은 대형 언어 모델이 실제로 언어를 이해하지 못하고 조작에만 뛰어나다는 점을 인정하지만, 빅 테크가 언어를 더 정확하게 조작하는 모델로 돈을 벌 수 있다는 이유 때문에 투자가 계속되고 있다. 게브루와 그녀의 동료들은 "이러한 연구 노력은 기회비용을 수반한다"고 쓰고 있다. 이해하는 데 도움을 주거나 더 작고 세심하게 큐레이션된 데이터 세트로 좋은 결과를 얻을 수 있는 AI 모델(따라서 더 적은 에너지를 사용하는 모델)의 개발에는 힘쓰지는 않는다는 것.
4. 의미에 대한 환상
큰 언어 모델의 마지막 문제는 그들이 진짜 인간의 언어를 흉내내는 것을 매우 잘하기 때문에 사람들을 멍청하게 만드는 데(easy to use them to fool people) 사용되기 쉽다는 점이다. 대학생이 블로그에서 AI가 만들어낸 자기 조력과 생산성 향상을 위한 조언을 대량 살포하여 세간의 이목을 집중시켰던 사례도 있었다. ... 페이스북은 2017년 아랍어로 '좋은 아침'이라고 적힌 팔레스타인 남성의 게시물을 히브리어로 '공격'으로 잘못 표기해 게시자가 체포되는 일도 있었다. ...
왜 문제가 되는가
...
공동 연구자인 Bender교수는 이 논문의 목표는 현재 진행 중인 자연어 처리 분야의 연구 환경을 신중하게 검토하는 것이었다고 말한다. “물건을 만드는 사람들이 실제로 자신들의 데이터를 팔로 감싸지 못하는 규모로 일하고 있습니다”라고 그녀는 주장한다. “그리고 그 상승세가 너무나 명백하기 때문에 한 발짝 물러서서 우리 자신에게 ‘어떤 문제점이 있을까? … 어떻게 하면 위험을 감소시키면서 이익을 취할 수 있을까?’하고 물어 보는 것이 특히 중요합니다.”
구글 AI 책임자인 딘은 내부 이메일을 통해 논문이 "우리 심사 기준을 통과하지 못한 이유 중 하나는 관련 연구를 너무 많이 무시했기 때문"이라고 주장했다. 구체적으로, 그는 대형 언어 모델의 에너지 효율을 높이고 편향성 문제를 완화하는 방법에 관한 최근의 연구가 언급되지 않았다고 말했다.
그러나 6명의 협력자들은 광범위한 분야에서 학위를 받은 사람들이다. ...
우리가 접한 버전의 논문도 대형 언어 모델의 크기와 계산 비용을 줄이고, 모델에 내재된 편향성을 측정하기 위한 몇 가지 연구 노력에 공감하고 있다. 그러나 이런 노력만으로는 부족하다고 주장하는 것이다. 벤더는, "나는 우리가 포함시켜야 할 다른 참고 자료에 무엇이 있을까를 바라보는 데 기꺼이 개방되어 있다"라고 말했다.
몬트리올 사무소의 구글 AI 연구원인 니콜라스 르루(Nicolas Le Roux)는 이후 트위터를 통해 딘의 이메일에 담긴 주장이 특이하다[신뢰하기 어렵다]고 지적했다. 그는 "내 출품작들은 민감한 자료의 개방에 대해서는 항상 점검받았으나, 문헌 평가의 질에 대해서는 결코 점검받은 적이 없었다"고 말했다.
딘은 자신의 이메일에서, 게브루와 동료들이 논문을 콘퍼런스에 제출하기에 앞서 내부 검토를 위해 구글 AI에 단 하루의 시간만 줬었다고 변명했다. 그는 "출판을 앞둔 연구 결과물을 어떻게 엄격하고 사려 깊게 리뷰하는지와 관련해서 전문가 동료들이 검토하는 [다른] 저널들과 경쟁하는 것이 우리의 목표"라고 썼다. ...
하지만 전 구글 홍보담당 매니저인 윌리엄 피츠제럴드(William Fitzgerald)를 포함하여 다른 이들은 딘의 이 주장에 대해 더욱 의문을 제기하고 있다.
“이건 순 거짓말이다. 구글 홍보팀에서 이 논문들을 검토하는 것이 내 일의 일부였는데, 전형적으로 있는 일이다. 논문들이 많았기 때문에 우리가 그것들을 제때 검토하지 못하기도 했었고, 어떤 연구자는 그냥 출판하고 우리가 나중에서야 그 사실을 알게 되곤 했었다. 하지만 우리는 여태 적절한 절차를 지키지 않았다고 해서 결코 그 연구자들을 처벌하진 않았었다.”
구글은 여지껏 대형 언어 모델의 폭발로 이어진 기초 연구의 많은 영역을 개척해 왔다. 구글 AI는 2017년 자사 후기 모델인 BERT와 OpenAI의 GPT-2, GPT-3의 기반이 되는 언어 번역 모델을 최초로 개발했다. BERT는 이제 회사의 캐시 카우(현금줄)인 구글 검색에도 힘을 보태고 있다.
벤더는 구글의 행동이 향후 AI 윤리 연구에 '사기 저하 효과'를 일으킬 수 있다고 우려한다. AI 윤리 분야 최고 전문가들 중 상당수가 대기업에서 근무하고 있는 것도 거기에 돈이 있기 때문이다. "그것[대기업 근무]은 이로운 점이 많았는데, 이제 우리는 어쩌면 세계를 위한 과학의 진보에 가장 크게 기여할 수 있는 인센티브가 아닌 다른 인센티브들을 지닌 생태 환경에서 멈추게 될지도 모른다"고 말한다.
에너지를 저 정도나 소비하는 줄 몰랐네 ㅎ. 구글은 물론 제프의 위신도 크게 추락할 듯.
그나저나 "네이버 클라우드 데이터센터 ‘각 세종’ 건립으로 단순한 기업 유치를 넘어 지역민과 대기업이 상생하는 새로운 모델을 만들어 갈 것”이고 “'각 세종’ 이 안전하게 건립될 수 있도록 행정적 지원을 아끼지 않을 것"이라던 세종시는 제대로 된 투자를 한 걸까 ...