https://arxiv.org/abs/2211.15006
Fine-tuning language models to find agreement among humans with diverse preferences
Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic
arxiv.org
https://blog.google/technology/ai/bard-google-ai-search-updates/
An important next step on our AI journey
Introducing Bard, Google's experimental conversational AI service powered by LaMDA — plus, new AI features in Search coming soon.
blog.google
"Fine-tuning language models to find agreement among humans with diverse preferences" 중에서
인간의 선호도를 조사하기 위한 언어 모델을 미세하게 조정하는 데 사용되는, 현존하는 강력하고 일반적인 방법은 인간의 선호를 동질적이고 정적인 것처럼 취급한다. 이 방법이 가정하고 있는 것은, 객관적으로 정의된 기준 진실, 즉 그 모델이 요약해야 하는 기사가 포함하고 있는 사실을 요약하는 작업(article summarisation)에 적합하다. 그러나 사람들이 언어를 사용하여 스스로 해결하는 다양한 사회 문제(예컨대, 사회적 공론화나 집단적 의사 결정)에 대해 모두 동일한 가치를 공유하고 있다고 가정할 수는 없다. 다양한 선호들을 조정하는 데 중요한 열쇠가 되는 사례 연구는 합의 형성(consensus formation)이다. 합의란, 일반적으로 특정 주제나 행위 과정에 대해 사회 집단의 상당 부분이 동의하는 것이라고 정의할 수 있다. 이는 협력의 전제 조건이자 민주적 절차의 핵심 기둥이다. 인간들 사이의 합의를 찾는 일은 쉽지 않으며, 기술은 종종 서로 다른 의견을 가진 사람들 사이의 화해를 조장하기보다는 정치적 분열을 심화시킨다. 대규모 언어 모델(large language models=LLMs)은 동종적 선호와 관련하여 놀라운 유연성과 민감성을 성취했지만, 사람들이 동의를 찾도록 돕는 능력을 가지고 있는지는 아직 시험된 적이 없다.
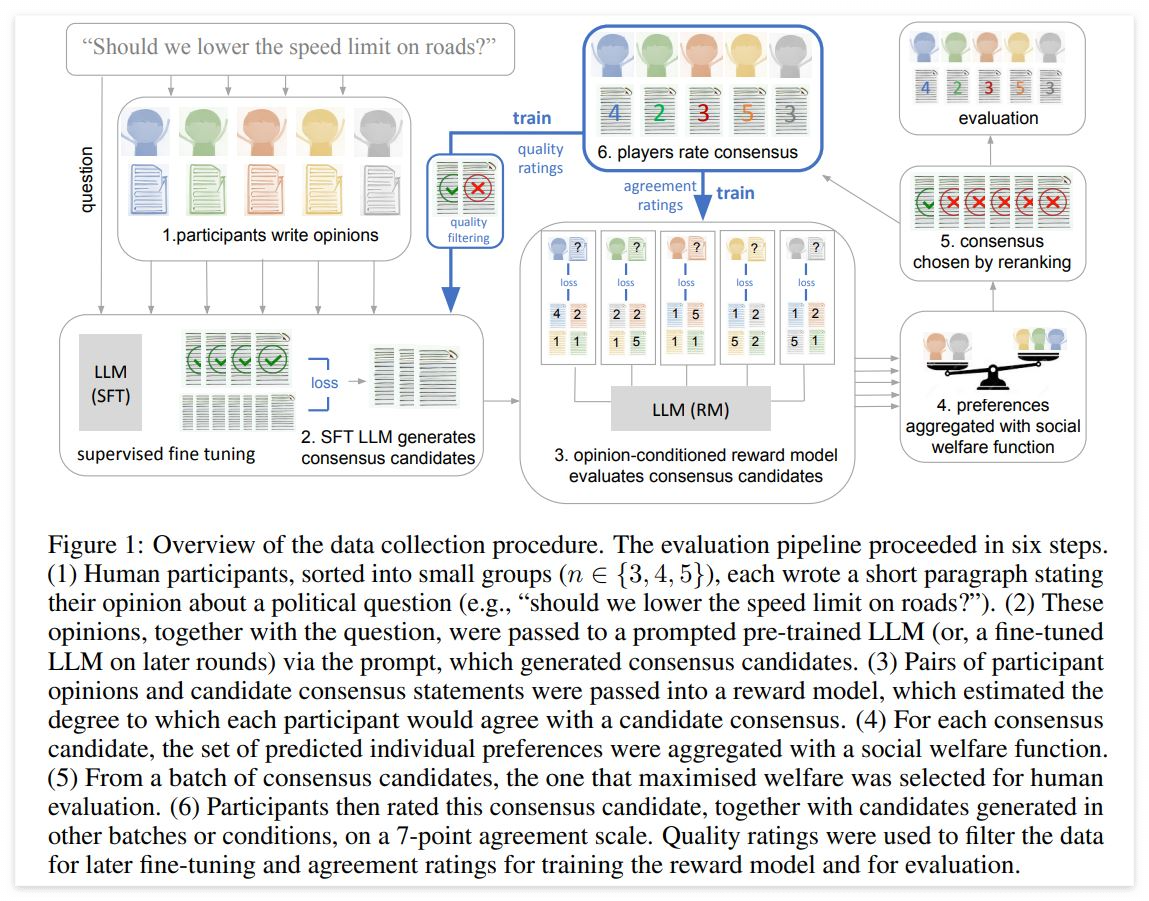
여기서 우리는 대규모 언어 모델을 사용하여 사용자 간의 승인 비율을 최대화하는 서면 의견을 집단적으로 생성하는 데 도움이 되는 연구를 수행한다. 구체적으로 말하자면, 우리는 합리적이고 충분한 정보를 가진 사람들이 합당하게 동의하지 않을 수도 있는, 영국의 정치적 문제에 관한 수천 개의 질문 말뭉치(corpus)를 만든다(예컨대, "건강에 해로운 음식과 단 음료에 세금을 부과해야 합니까?" 또는 "철도를 다시 국유화해야 합니까?”). 우리는 이러한 질문들에 대한 의견을 작성할 인간 참가자단을 모집한다. 그런 다음 700억 개의 매개 변수 언어 모델(Chinchilla)을 미세 조정하여 소그룹의 참가자가 지지할 가능성이 있는 합의 진술 후보들을 생성하고, 이것에 기본 사회 복지 함수(an underlying family of social welfare function)를 반영한다. 중요한 부분은, 우리의 작업에서 언어 모델은 특정 의견을 채택하거나 다른 사람에게 어느 한 가지 견해를 설득하도록 훈련받지 않는다는 사실이다. 오히려 인간 집단이 내놓은 의견을 바탕으로 합의 후보를 만들어 내도록 훈련된다. 우리는 특정 데이터 집합과 교육 파이프라인(particular data collection and training pipeline)이, 개인의 의견을 포함하여 여러 고성능 기준선(a number of high-performing baselines)보다 더 강력하게 선호되는 진술을 생성하는 모델을 결과로서 만들어 낸다는 사실을 발견했다. 모델이 생성한 진술은 사용자가 제공한 기본 의견을 반영한 것이다. 이 작업은 사람들이 대규모 언어 모델을 사용하여 집단적 의사 결정 서비스에서 공통분모를 찾을 수 있도록 도울 수 있는 새로운 가능성을 열어준다. …
우리의 작업은 의견-조건부 보상 모델링과 그룹 수준 복지 최대화의 조합(a combination of opinion-conditional reward modelling and group-level welfare maximisation)을 통해 특정 그룹에서 의견의 일치를 낳을 수 있을 진술들을 산출하도록 최적화한다. ...
이러한 프로젝트는 원래 의견을 제공한 사람들을 배제함으로써 조정 관련 문제를 유발하지 않으며 오히려 여타의 요약 작업에 더 가깝다. ...
우리의 작업은, 민주적인 숙의의 과정을 포함, 인간의 집단 이성을 촉진하기 위해 기계 학습 방법을 내용으로 한 기술을 사용하는 것에 대해 급속히 성장하고 있는 관심과 관련이 있다. ...
사전에 훈련된 700억 개의 매개변수를 반영한(prompted) 대규모 언어 모델(Chinchilla)을 사용하여 질문을 생성한다. 우리는 현대의 토론 이슈들에 대해 손으로 쓴 152개의 질문을 종자로 삼아 프로세스를 진행했다. 그것들은 대부분 "Should we ... ?" 또는 "Should the government ... ?" 형식의 정책 관련 질문들로서 인간 평가단에 참여한 영국 거주 기반 참가자들과 관련이 있는 질문들이다. 우리는 이 152개의 종자 질문을 사용하여 총 3500개의 토론 질문을 인위적으로 생성한다. 그리고 각 토론 질문에 대해 Chinchilla에게 10개의 종자 질문 샘플을 제공한다. 그러면 모델은 새로운 질문을 생성하는데, 이 질문이 유니크한 것일 경우 전체 세트에 추가한다. 우리는 수동으로 질문을 확인하고 사용자로부터 극단주의적 견해나 차별적 언어를 이끌어낼 가능성이 있다고 생각되는 질문을 필터링한다.
그 결과로 2922개의 질문이 생성되는데, 이것들을 다시 주제에 따라 클러스터링하여 하나의 훈련 세트와 두 개의 테스트 질문 세트를 만드는 데 사용한다. 먼저 범용 문장 인코더(Universal Sentence Encoder)를 사용하여 각 질문들을 [절(節)들로] 결합하고, 다시 k-평균 클러스터링을 사용하여 질문을 110개의 주제군(群)으로 만든다. 예를 들어, "정크 푸드에 세금을 부과해야 합니까?"라든가 "음식이나 식료품에 대한 모든 세금을 폐지해야 합니까?"와 같은 식료품세에 대한 질문에 해당하는 25개의 질문 클러스터가 있다. 그런 다음 클러스터를 두 그룹으로 나누어, 분포 외 보류 세트(n = 302)를 위해 일부 질문 클러스터를 따로 설정한다. 나머지 질문들은 교육(n = 2320개 질문)과 분포 내 보류 세트(n = 300)로 분류된다. ...
인간 평가단 참가자들은 자신의 의견을 제시하거나 합의 진술 후보를 보기 전에 선언 형식으로 진술된 질문의 버전이라고 할 수 있는 "입장 진술"(position statement)에 대해 동의 등급을 제공했다(예컨대, "We should ... "). 이를 통해 그룹 간의 기본 불일치를 측정할 수 있었다. 각 교육 또는 평가 세션은 45분에서 1시간 사이였다. 우리의 명백한 목표는 다양한 의견에 대해 교육하고 평가하는 것이므로 동일한 참가자를 반복적으로 사용하는 대신 데이터 수집 세션마다 새로운 참가자단을 모집했다. 참가 보상을 포함한 연구 설계의 전체 세부 사항은 독립적인 윤리 검토 위원회에서 검토했다. 모든 참가자는 작업을 완료하기 전에 정보에 입각한 동의를 제공받았으며 시간에 대한 보상을 받았다. 연구원이 근로자/참가자에게 해당 지역의 최소 임금을 지불하는 것이 우리의 정책이었고, 이 연구에서 참가자들은 시간당 평균 £15의 보상을 받았다(연구의 총 비용은 약 £46,000였다). ...
우리는 우선 한 그룹이 다른 정책보다 어느 한 정책을 선호할 가능성이 얼마나 되는지를 비교하는데, 이때 두 가지 메트릭스를 사용하여 이를 수행하였다. 그룹 전체의 평균 동의(모델의 공리주의적 교육 목표와 일치), 그리고 그룹의 최소 동의(롤즈의 목표와 일치하며 모델에서 명시적으로 사용되지 않음).

■ 챗-GPT(Generative Pre-trained Transformer), you.com, Bard 같은 의사소통+검색+과제 해결 인공지능 봇이 사용한다는 SFT(Supervised fine-tuning)-Utilitarian Model이 우리 삶에 어떤 변화를 가져올까?
실존적 결단이 요구되는 문제의 경우 (ex -, 내가 죽을 시기를 결정하는 일; 평생 함께 할 배우자를 선택하는 일; 내가 겪고 있는 일이나 경험의 의미를 이해하는 일 등)에도 타자들의 시선과 그 눈높이에 따르게 될 수밖에 없을 듯하다.
AI가 제공하는 결과물을 전적으로 신뢰하는 것이 아니라 그저 참고하기만 한다고 하더라도, 장기적으로는 인간 개인이 각자의 능력 - 그것이 어떤 종류의 것이든 우리를 인간으로 만들어 주는 능력 (ex-, 인내심, 희생이나 헌신, 모험심, 포용력 etc.)이지만, 그 발휘의 최대치를 현실에서는 극소수에게서만 기대할 수 있을 그런 능력)을 더 이상 사용하거나 계발하고자 하지 않게 될 것 같다.
그러나 더 중요한 문제의 핵심은, 그 같은 능력은 우리가 직접 사용해 봄으로써만 계발할 수 있고 또 자신이 그것을 가지고 있다는 사실을 이해하게 되는 성격의 능력이라는 점이리라. 만일 이런 생각이 근거 없는 망상이 아니라면, 챗-GPT를 즐겨 사용하는 인간은 자기를 초월하려는 시도를 절약하려고만 하게 되고, 다수에게 긍정되고 수용되는 - 챗봇이 생성해 준 - summary적 관점에 따라 사고하고 행동하고 대인 관계를 맺게 되지 않을까? 그래서 실존철학자들이 지난 세기 그렇게도 혐오했던 일상인(das Man)의 관점, 객관적 시선(L’enfer, c'est regard des autres.)에 맞추어진 삶의 모습이 만연하게 되는 건 아닐지? 정확히 이해하지는 못하겠지만 Utilitarian Model을 Rawlsian & Bernoulli-Nash적 함수로 보정해 주는 과정이 있다고는 하는데, 그렇다고 preference 공리주의의 특성상 최대 다수를 '입 닥치게' 만드는 결과 이상을 기대할 수 있을까?
제안: 합의 도달이 가능한 진술 후보자들을 찾는 데서 멈추지 말고 극단적 의견을 담고 있는 진술 후보자들 역시 옵션으로 보여주는 모델링으로 보완해 보면 어떨까? 괴짜 취급받고 극강의 시도를 두려워하지 않는 인간들이 계속 나타나야 하니까.